
如何将谷歌开源的V8引擎移植到纯血鸿蒙系统?
↓ 点击下方卡片关注「OSC开源社区」
01
背景
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
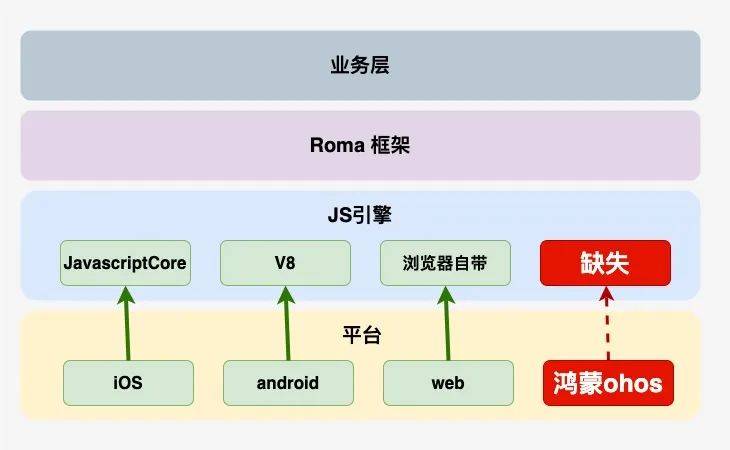
如图所示, Roma框架是我们自主研发的 动态化跨平台解决方案,已支持 iOS,android,web三端。目前在京东金融APP已经有200+页面,200+乐高楼层使用,为保证基于Roma框架开发的业务可以零成本、无缝运行到鸿蒙系统,需要将Roma框架适配到鸿蒙系统。
Roma框架是基于JS引擎运行的,在iOS系统使用系统内置的JavaCore,在Android系统使用V8,然而, 鸿蒙系统当时却没有可以执行Roma框架的JS引擎,因此 需要移植一个JS引擎到鸿蒙平台。
02
JS引擎选型
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
目前主流的JS引擎有以下这些:
引擎名称
应用代表
公司
V8
Chrome/Opera/Edge/Node.js/Electron
SpiderMonkey
firefox
Mozilla
JavaCore
Safari
Apple
Chakra
IE
Microsoft
Hermes
React Native
Jerry/duktape/QuickJS
小型并且可嵌入的Java引擎/主要应用于IOT设备
展开全文
其中最流行的是 Google开源的V8引擎,除了 Chrome等浏览器, Node.js也是用的V8引擎。Chrome的市场占有率高达60%,而Node.js是JS后端编程的事实标准。另外, Electron(桌面应用框架)是基于Node.js与Chromium开发桌面应用,也是基于V8的。国内的众多浏览器,其实也都是基于 Chromium浏览器开发,而Chromium相当于开源版本的Chrome,自然也是基于V8引擎的。甚至连浏览器界独树一帜的 Microsoft也投靠了Chromium阵营。V8引擎使得JS可以应用在 Web、APP、桌面端、服务端以及IOT等各个领域。
03
V8移植工具选型
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
我们的开发环境各式各样可能系统是Mac,Linux或者Windows,架构是x86或者arm,所以要想编译出可以跑在鸿蒙系统上的v8库我们需要使用 交叉编译,它是在一个平台上为另一个平台编译代码的过程,允许我们在一个平台上为另一个平台生成可执行文件。这在嵌入式系统开发中尤为常见,因为许多嵌入式设备的硬件资源有限,不适合直接在上面编译代码。

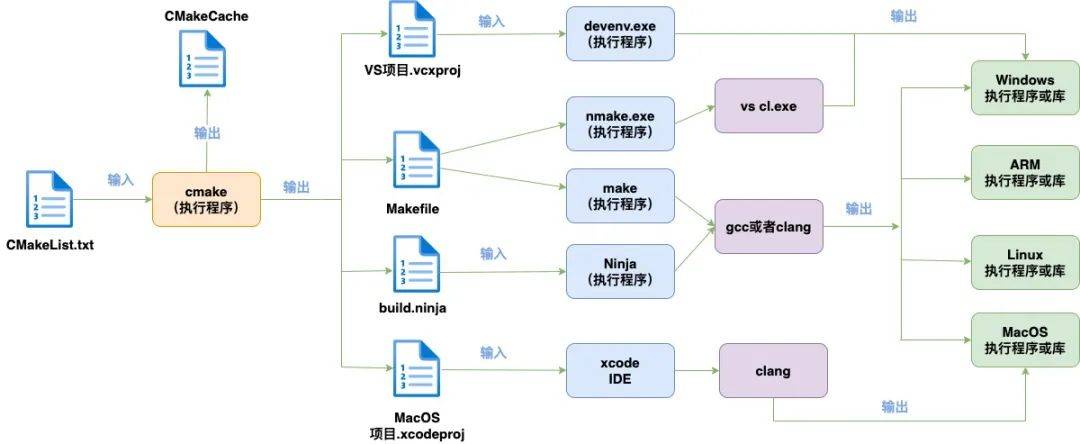
v8官网上关于交叉编译Android和iOS平台的V8已经有详细的介绍。尚无关于鸿蒙OHOS平台的文档。V8官方使用的构建系统是 gn + ninja。 gn是一个 元构建系统,最初由Google开发,用于生成 Ninja文件。它提供了一个声明式的方式来定义项目的依赖关系、编译选项和其他构建参数。通过运行 gn gen命令,可以生成一个 Ninja文件。类似于 camke + make构建系统。
gn + ninja的构建流程如下:
通过查看 鸿蒙sdk,我们发现鸿蒙提供给开发者的native构建系统是 cmake + ninja,所以我们决定将v8官方采用的 gn + ninja转成 cmake + ninja。这就需要将gn语法的构建配置文件转成cmake的构建配置文件。
1. CMake简介
CMake是一个开源的、跨平台的构建系统。它不仅可以生成标准的 Unix Makefile配合 make命令使用,还能够生成 build.ninja文件配合 ninja使用,还可以为多种 IDE生成项目文件,如 Visual Studio、Eclipse、Xcode等。这种跨平台性使得 CMake在多种操作系统和开发环境中都能够无缝工作。
cmake的构建流程如下:
CMake构建主要过程是编写 CMakeLists.txt文件,然后用cmake命令将CMakeLists.txt文件转化为make所需要的Makefile文件或者ninja需要的build.ninja文件,最后用 make命令或者 ninja命令执行编译任务生成可执行程序或共享库(so(shared object))。
2. CMake中的交叉编译设置
CMake中可以使用工具链文件进行交叉编译设置, 工具链文件(toolchain file)是将配置信息提取到一个单独的文件中,以便于在多个项目中复用。包含一系列CMake变量定义,这些变量指定了编译器、链接器和其他工具的位置,以及其他与目标平台相关的设置,以确保它能够正确地为目标平台生成代码。
一个基本的工具链文件示例如下:
创建一个名为 toolchain.cmake的文件,并在其中定义工具链的路径和设置:
该项目需要为ARM架构的Linux系统进行交叉编译
# 设置链接器set(CMAKE_LINKER "/path/to/linker")
# 指定目标系统的类型 set(CMAKE_SYSTEM_NAME Linux) set(CMAKE_SYSTEM_PROCESSOR arm)
# 其他与目标平台相关的设置 # ...
在执行 cmake命令构建时,使用 -DCMAKE_TOOLCHAIN_FILE参数指定工具链文件的路径:
这样,CMake就会使用工具链文件中指定的编译器和设置来为目标平台生成代码。
04
V8和常规C++库移植的重大差异
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
一般的库,所谓交叉编译就是调用目标平台指定的工具链直接编译源码生成目标平台的文件。比如一个C文件要给android用,调用ndk包的gcc、clang编译即可。但由于v8的builtin和snapshot用的是v8自己的工具链体系编译成目标平台的代码,所以并不能直接套用这种方式。
1. builtin1.1 builtin是什么
在V8引擎中,builtin即内置函数或模块。V8的内置函数和模块是Java语言的一部分,提供了一些基本的功能,例如数学运算、字符串操作、日期处理等,这些内置函数和模块是通过C++代码实现的,并在编译时直接集成到V8引擎中,不需要在Java代码中显式地导入或引用,就可以直接使用。另外ignition解析器每一条字节码指令实现也是一个builtin。
1.2 builtin是如何生成的
v8源码中 builtin的编译比较绕,因为v8中大多数 builtin的“源码”,其实是 builtin的生成逻辑,这也是理解V8源码的关键。
builtin和 snapshot都是通过 mksnapshot工具运行生成的。 mksnapshot是v8编译过程中的一个中间产物,也就是说v8编译过程中会生成一个 mksnapshot可执行程序并且会执行它生成v8后续编译需要的builtin和snapshot,就像套娃一样。
例如v8源码中 字节码Ldar指令的实现如下:
上述代码只在V8的 编译阶段由 mksnapshot程序执行,执行后会产出机器码( JIT),然后 mksnapshot程序把生成的机器码dump下来放到汇编文件 embedded.S里,编译进V8运行时(相当于用 JIT编译器去 AOT)。
上述 Ldar指令dump到 embedded.S后汇编代码如下:
builtin在v8源代码 v8\src\builtins\builtins-definitions.h中定义,这个文件还include一个根据 ignition指令生成的builtin列表以及 torque编译器生成的builtin定义,一共 1700+个builtin。每个builtin,都会在 embedded.S中生成一段代码。builtin生成的v8源代码在: v8\src\builtins\setup-builtins-internal.cc文件, 其中BUILTIN_LIST宏内定义了所有的builtin,并根据其类型去调用不同的参数,参数有BUILD_CPP, BUILD_TFJ...这些,定义了不同的生成策略,这些参数去掉前缀代表不同的builtin类型( CPP, TFJ, TFC, TFS, TFH, BCH, ASM)。
mksnapshot执行时生成builtin的方式有两种:
直接生成机器码,ASM和CPP类型builtin使用这种方式(CPP类型只是生成适配器)
先生成 turbofan的 graph(IR),然后由turbofan编译器编译成机器码,除ASM和CPP之外其它builtin类型都是这种
先生成 turbofan的 graph(IR),然后由turbofan编译器编译成机器码,除ASM和CPP之外其它builtin类型都是这种
例如: DoubleToI是一个 ASM类型builtin,功能是把double转成整数,该builtin的JIT生成逻辑位于 Builtins::Generate_DoubleToI,如果是x64的window,该函数放在 v8/src/builtins/x64/builtins-x64.cc文件。由于每个CPU架构的指令都不一样,所以每个CPU架构都有一个实现,放在各自的 builtins-ArchName.cc文件。
除了ASM和CPP的其它类型builtin都通过调用 CodeStubAssembler API(下称 CSA)编写,这套API和之前介绍ASM类型builtin时提到的“类汇编API”类似,不同的是“类汇编API”直接产出原生代码,CSA产出的是 turbofan的 graph(IR)。CSA比起“类汇编API”的好处是不用每个平台各写一次。但是类汇编的CSA写起来还是太费劲了,于是V8提供了一个 类java的高级语言: torque,这语言最终会编译成 CSA形式的c++代码和V8其它C++代码一起编译。
例如 Array.isArray使用 torque语言实现如下:
namespacearray { // ES #sec-array.isarrayjava builtin ArrayIsArray(js-implicit context: NativeContext)(arg: JSAny):JSAny {// 1. Return ? IsArray(arg).typeswitch (arg) {case(JSArray): { returnTrue; }case(JSProxy): { // TODO(verwaest): Handle proxies in-placereturnruntime::ArrayIsArray(arg); }case(JSAny): { returnFalse; }}}} // namespace array
经过 torque编译器编译后,会生成一段复杂的 CSA的C++代码,下面截取一个片段
和上面讲的 Ldar字节码一样,这并不是跑在v8运行时的Array.isArray实现。这段代码只运行在 mksnapshot中,这段代码的产物是turbofan的IR。IR经过turbofan的优化编译后生成目标机器指令,然后dump到 embedded.S汇编文件,下面才是真正跑在v8运行时的Array.isArray:
在这个过程中,JIT编译器turbofan同样干的是AOT的活。
2. snapshot
在V8引擎中,snapshot是指将部分或全部Java堆内存的状态保存到一个文件中,以便在后续的启动中可以快速恢复到这个状态。当V8引擎启动时,如果存在有效的Snapshot文件,V8会直接从这个文件中读取Java堆的状态和字节码,而不需要重新解析和编译所有的Java代码。这可以大幅度缩短V8引擎的启动时间,特别是在大型应用程序中。
如果不是交叉编译,snapshot生成还是挺容易理解的:v8对各种对象有做了 序列化和反序列化的支持,所谓生成 snapshot,就是 序列化,通常会以context作为根来序列化。
在交叉编译时,JIT生成的builtin是目标机器指令,而js的运行得通过跑builtin来实现(Ignition解析器每个指令就是一个builtin),这目标机器指令(比如arm64)怎么在本地(比如linux 的x64)跑起来呢?是因为 mksnapshot为了实现交叉编译中目标平台snapshot的生成,做了 各种cpu(arm、mips、risc、ppc)的模拟器(Simulator),相关模拟器的实现在v8/src/execution/simulator-ArchName.h,v8/src/execution/simulator-ArchName.cc文件中。
05
V8移植的具体步骤
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
一般我们将负责编译的机器称为 host,编译产物运行的目标机器称为 target。
本文使用的host机器是Mac M1 ,Xcode版本Version 14.2 (14C18)
鸿蒙IDE版本:DevEco Studio NEXT Developer Beta5
鸿蒙SDK版本是HarmonyOS-NEXT-DB5
目标机器架构: arm64-v8a
目标机器架构: arm64-v8a
如果要在 Mac M1上交叉编译鸿蒙 arm64的builtin,步骤如下:
调用本地编译器,编译一个Mac M1版本mksnapshot可执行程序
执行上述mksnapshot生成鸿蒙平台arm64指令并dump到embedded.S
调用 鸿蒙sdk的工具链,编译链接 embedded.S和v8的其它代码,生成能在鸿蒙arm64上使用的v8库
调用 鸿蒙sdk的工具链,编译链接 embedded.S和v8的其它代码,生成能在鸿蒙arm64上使用的v8库
鸿蒙sdk自带构建工具我们可以将它们加入环境变量中使用
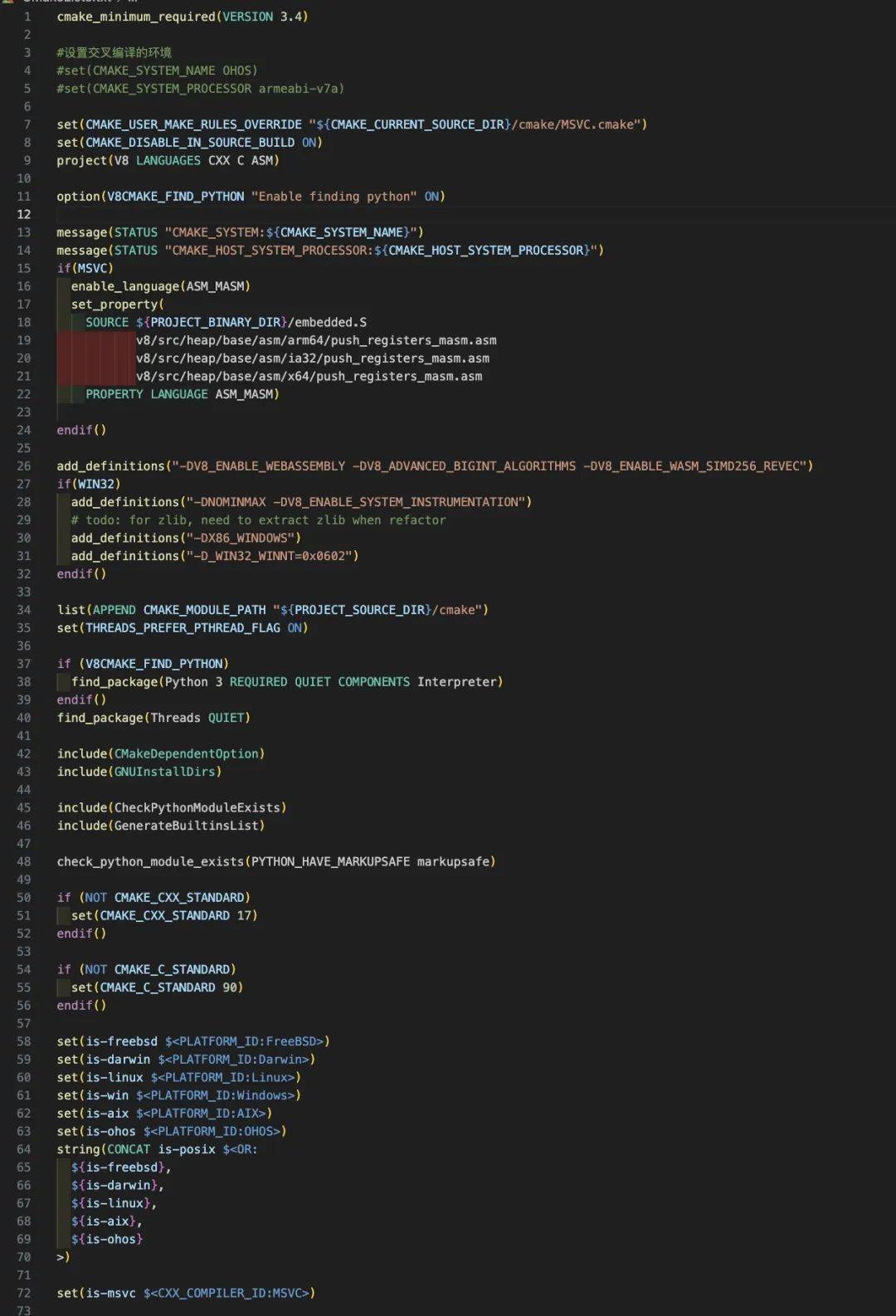
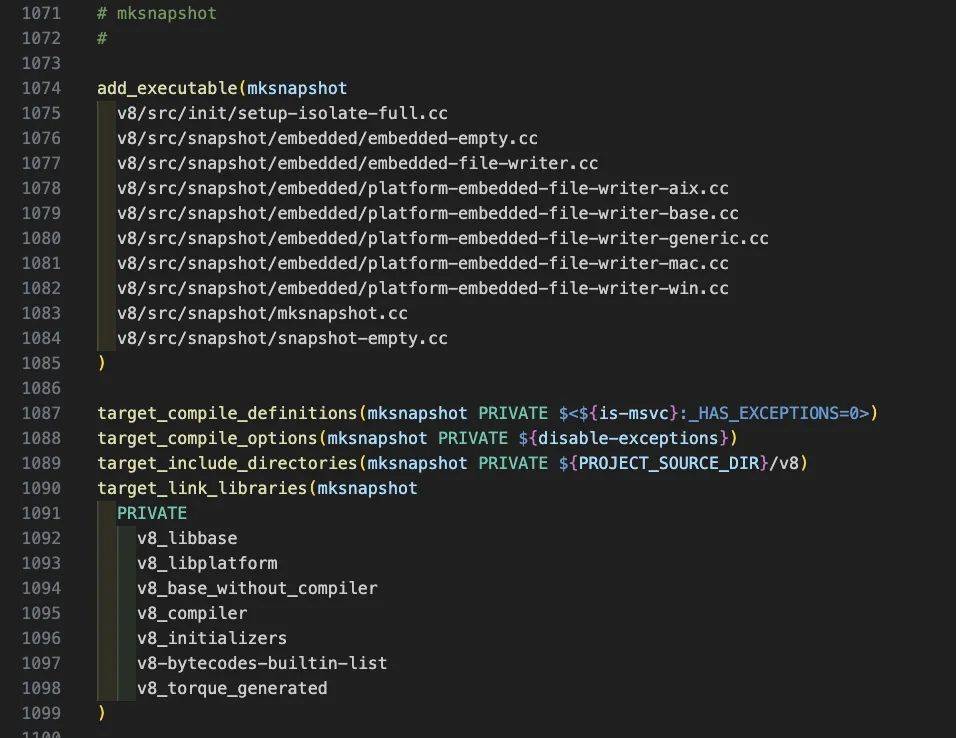
2. 编写交叉编译V8到鸿蒙的CMakeList.txt
总共有1千多行,部分 CMakeList.txt片段:
3. 使用host本机的编译工具链编译
$cdbuild
$cmake -G Ninja ..
$ninja 或者 cmake --build .
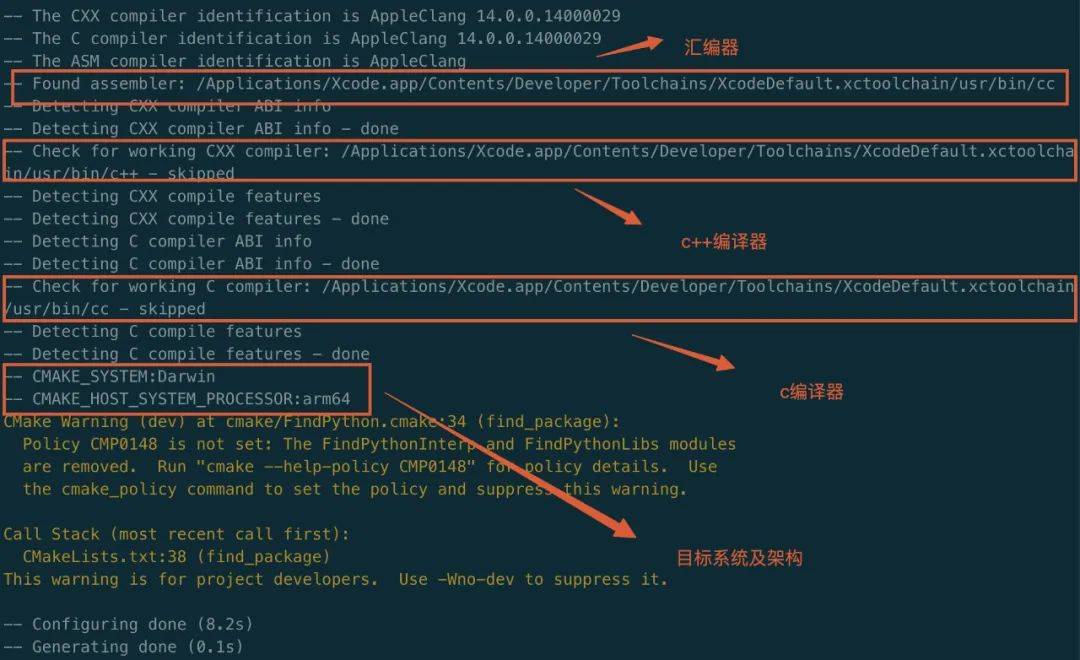
首先创建一个编译目录 build,打开 build执行 cmake -G Ninja ..生成针对n inja编译需要的文件。
下面是控制台打印的工具链配置信息,使用的是Mac本地xcode的工具链:
build文件夹下生成以下文件:
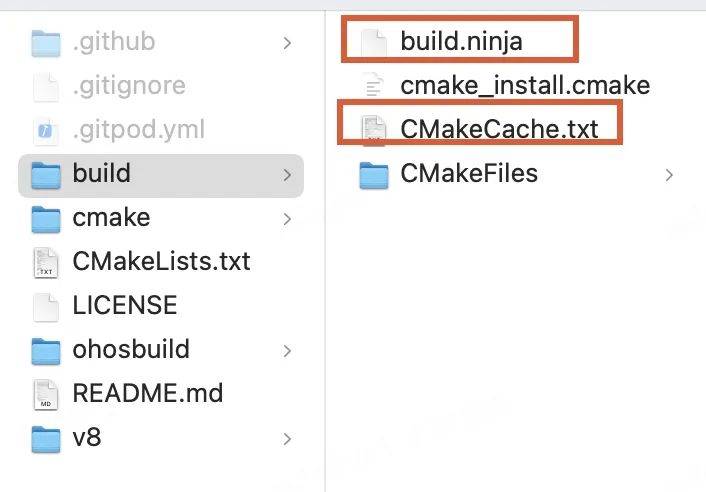
其中 CMakeCache.txt是一个由CMake生成的缓存文件,用于存储CMake在配置过程中所做的选择和决策。它是根据你的项目的 CMakeLists.txt文件和系统环境来生成一个初始的 CMakeCache.txt文件。这个文件包含了所有可配置的选项及其默认值。 build.ninja文件是 Ninja的主要输入文件,包含了项目的所有构建规则和依赖关系。
然后执行 cmake --build. 或者 ninja
查看 build文件夹下生成的产物:
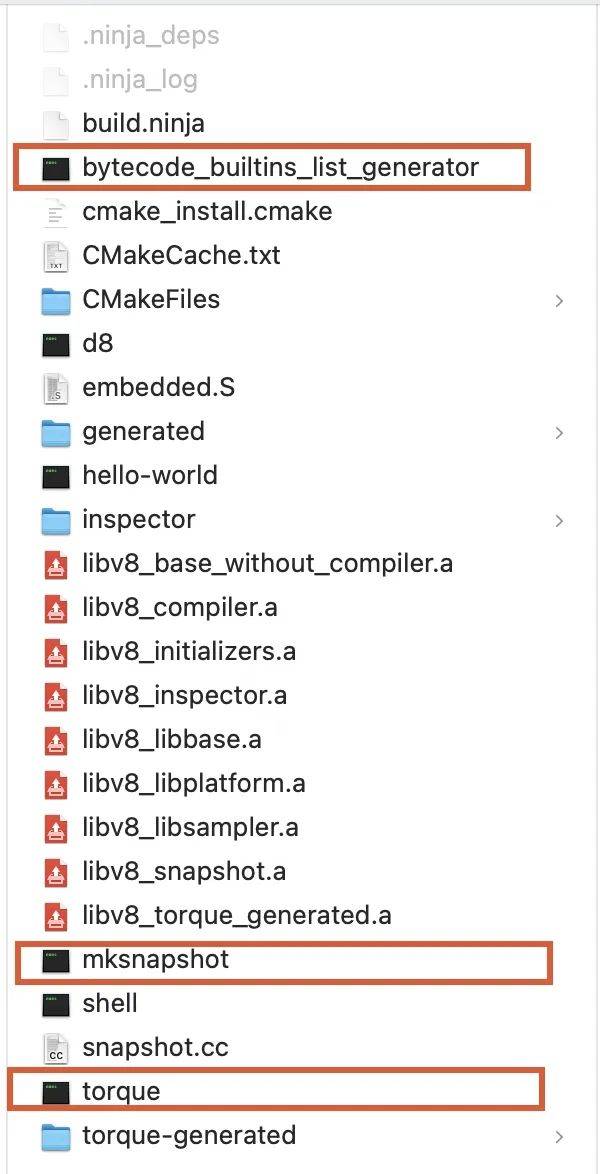
其中红框中的三个可执行文件是在编译过程中生成,同时还会在编译过程中执行。 bytecode_builtins_list_generator主要生成是字节码对应builtin的生成代码。 torque负责将 .tq后缀的文件(使用 torque语言编写的builtin)编译成 CSA类型builtin的c++源码文件。
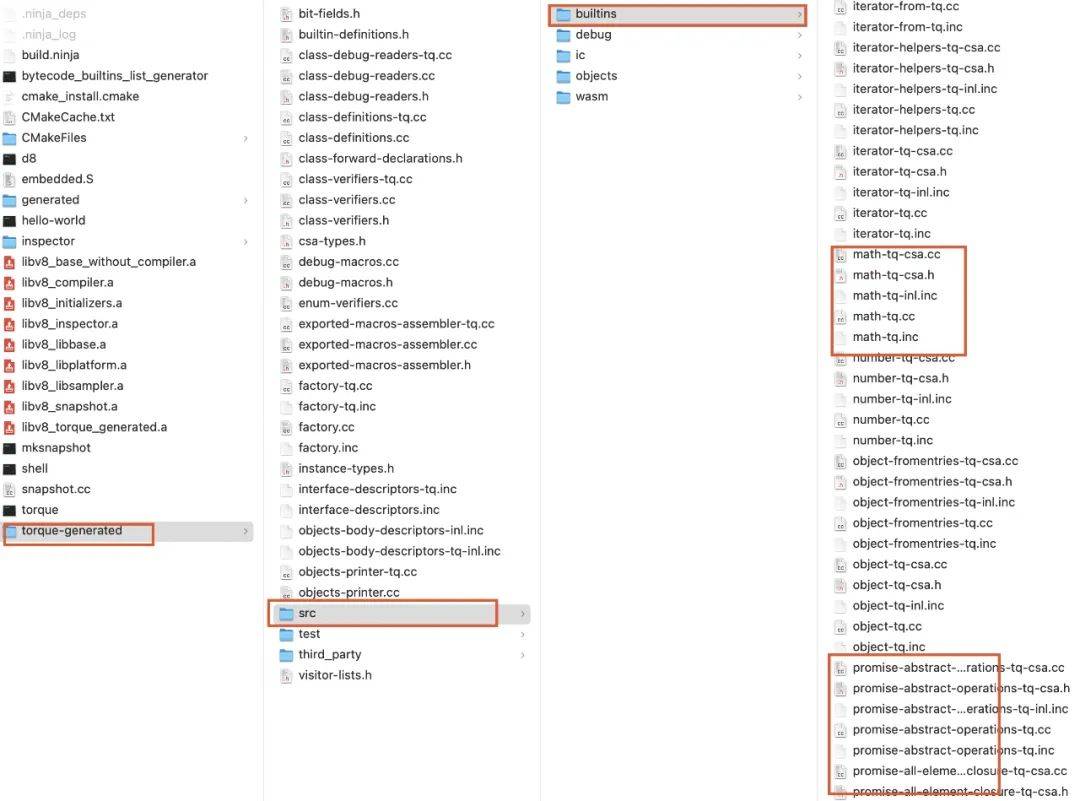
torque编译 .tq文件生成的c++代码在 torque-generated目录中:
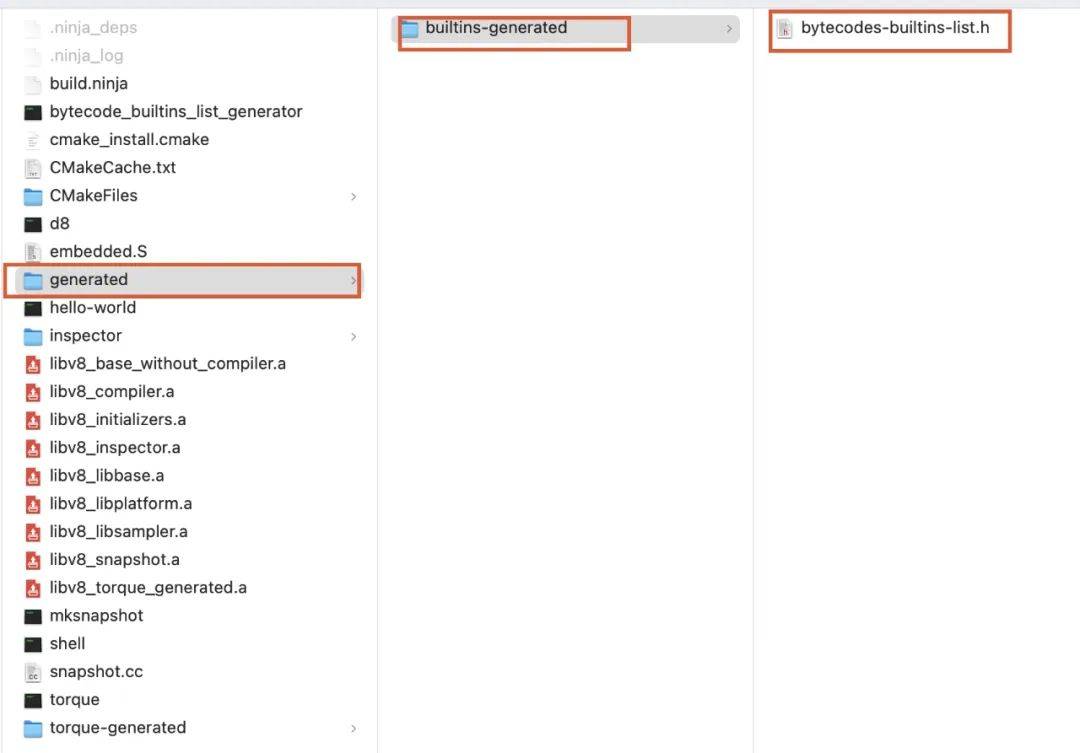
bytecode_builtins_list_generator执行生成字节码函数列表在下面目录中:
mksnapshot则链接这些代码并执行,执行期间会在内置的对应架构模拟器中运行v8,最终生成host平台的 buildin汇编代码——embedded.S和snapshot(context的序列化对象)——snapshot.cc。它们跟随其他v8源代码一起编译生成最终的v8静态库 libv8_snapshot.a。目前build目录中已经编译出host平台的完整v8静态库及命令行调试工具 d8。
mksnapshot程序自身的编译生成及执行在 CMakeList.txt中的配置代码如下:
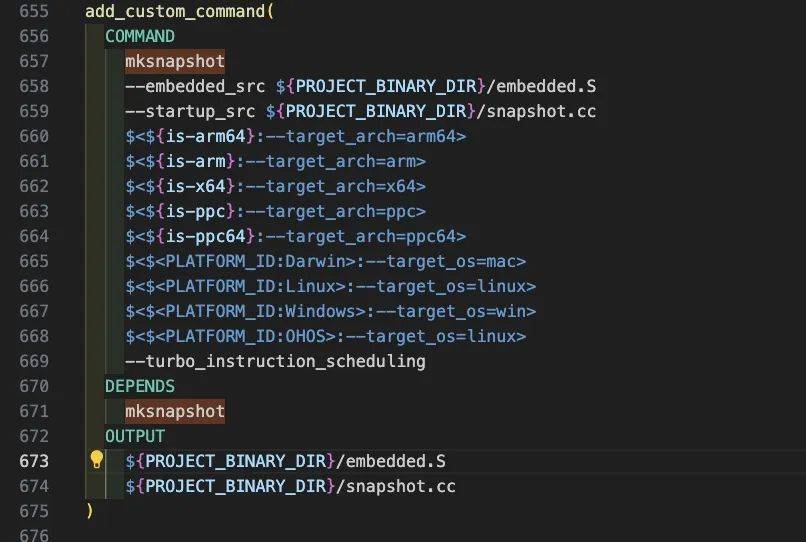
4. 使用鸿蒙SDK的编译工具链编译
因为在编译target平台的v8时中间生成的 bytecode_builtins_list_generator, torque, mksnapshot可执行文件是针对target架构的无法在host机器上执行。所以首先需要把上面在host平台生成的可执行文件拷贝到 /usr/local/bin,这样在编译target平台的v8过程中执行这些中间程序时会找到 /usr/local/bin下的可执行文件正确的执行生成针对target的builtin和snapshot快照。
$mkdir ohosbuild #创建新的鸿蒙v8的编译目录
$cdohosbuild
#使用鸿蒙提供的工具链文件
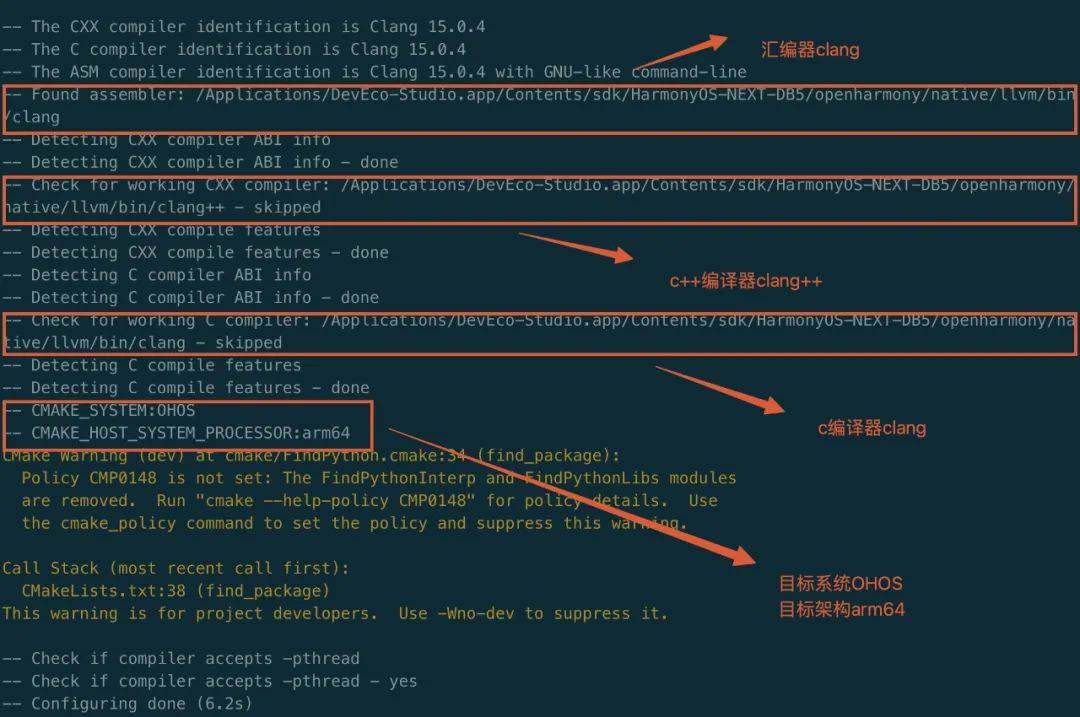
$cmake -DOHOS_STL=c++_shared -DOHOS_ARCH=arm64-v8a -DOHOS_PLATFORM=OHOS -DCMAKE_TOOLCHAIN_FILE=/Applications/DevEco-Studio.app/Contents/sdk/HarmonyOS-NEXT-DB5/openharmony/native/build/cmake/ohos.toolchain.cmake -G Ninja ..
$ninja 或者 cmake --build .
执行第一步cmake配置后控制台的信息可以看到,使用了鸿蒙的工具链
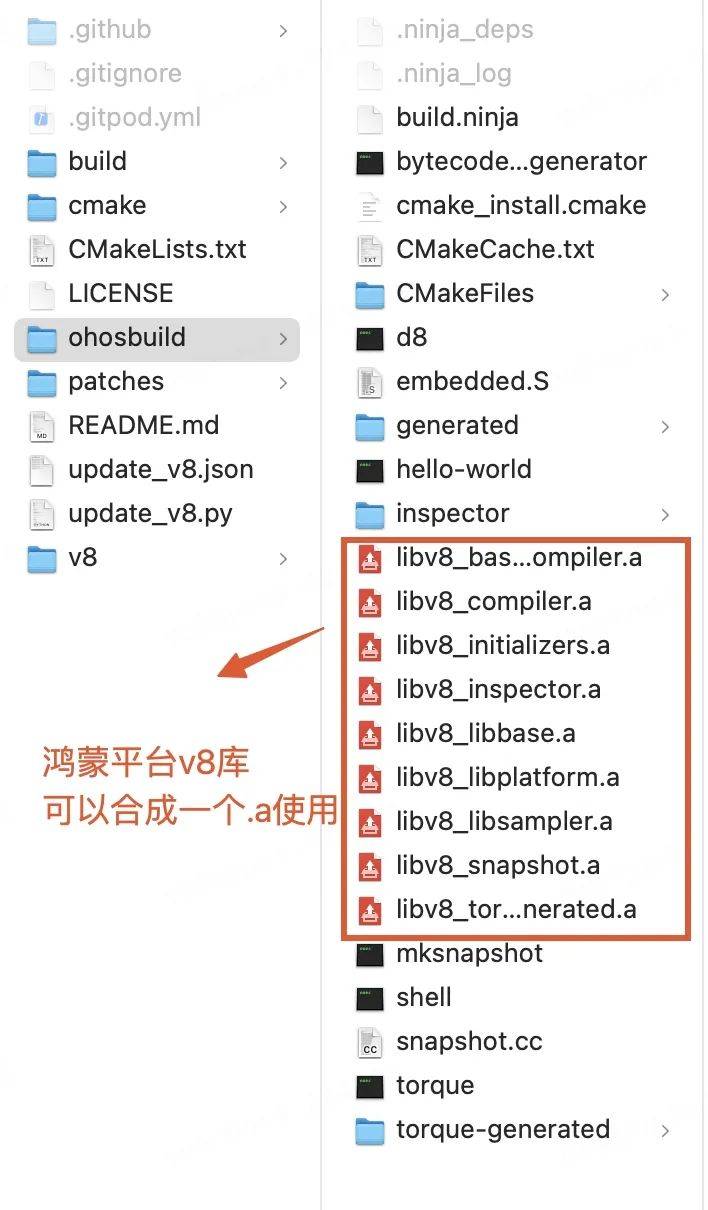
执行完成后 ohosbuild文件夹下生成了鸿蒙平台的v8静态库,可以修改 CMakeList.txt配置合成一个.a或者生成.so。
06
鸿蒙工程中使用V8库
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
1. 新建native c++工程
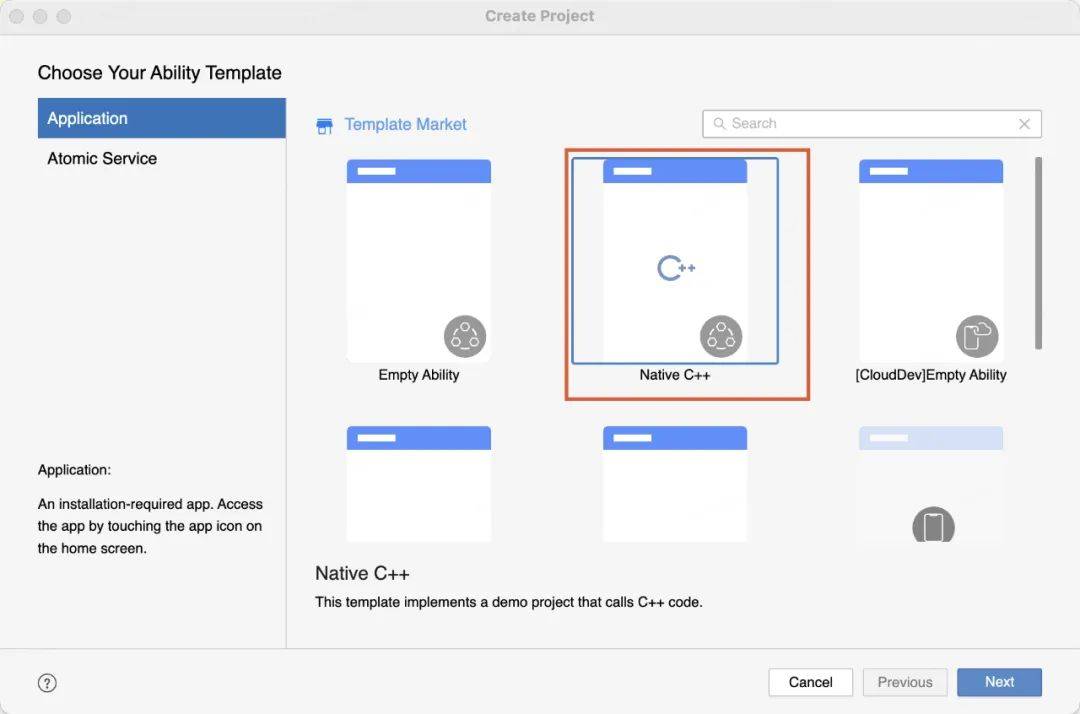
2. 导入v8库
将v8源码中的include目录和上面编译生成的.a文件放入cpp文件夹下
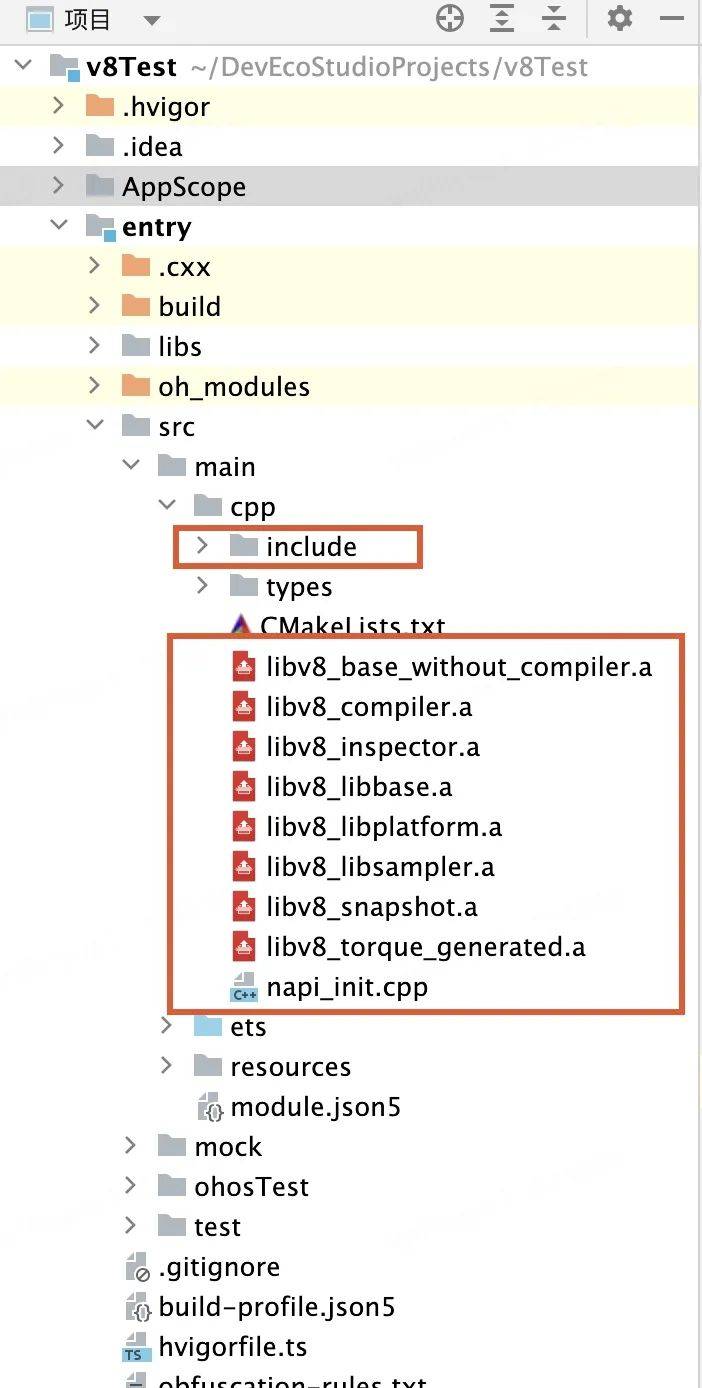
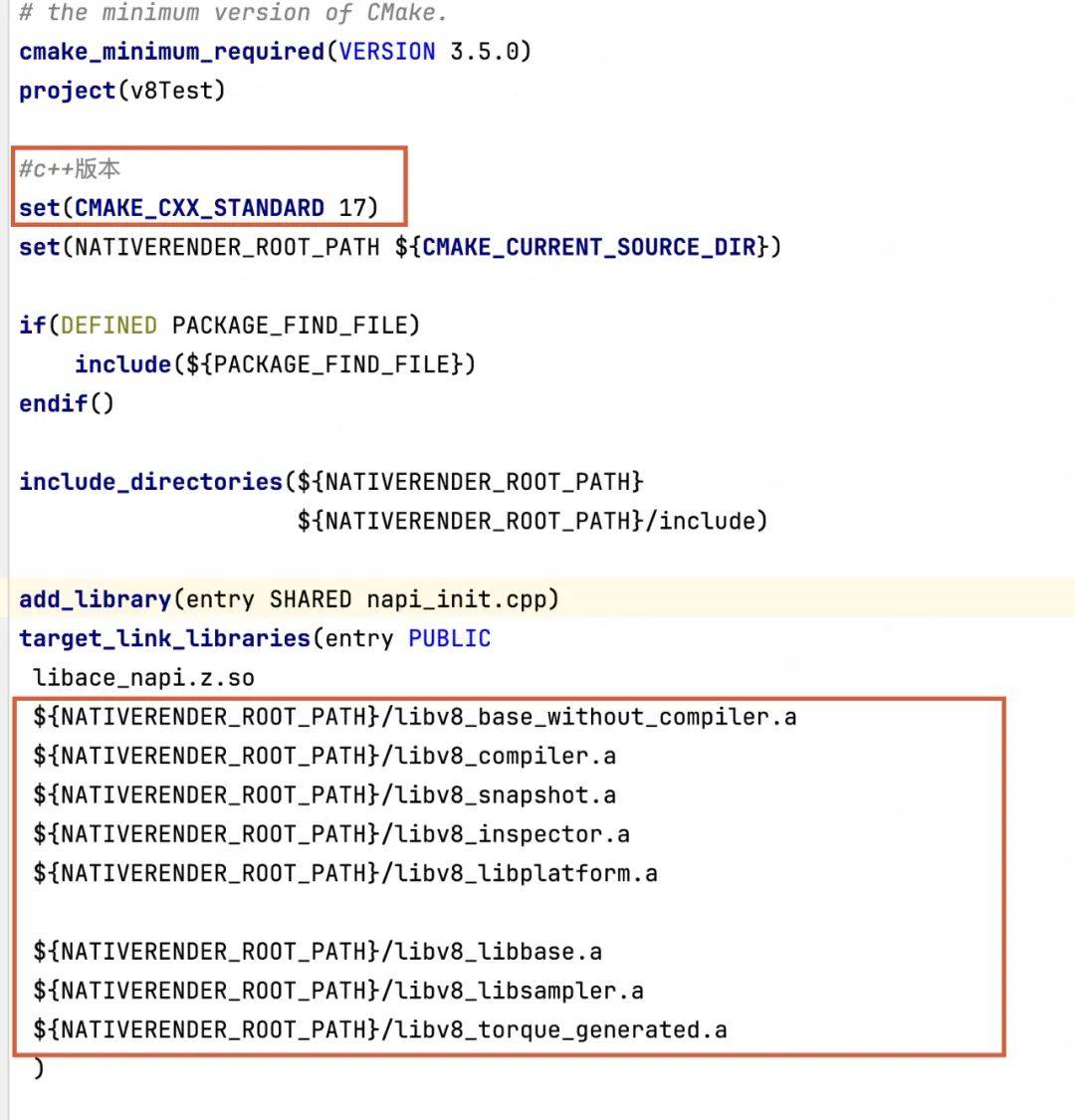
3. 修改cpp目录下CMakeList.txt文件
设置c++标准17,链接v8静态库
4. 添加napi方法测试使用v8
下面是简单的demo
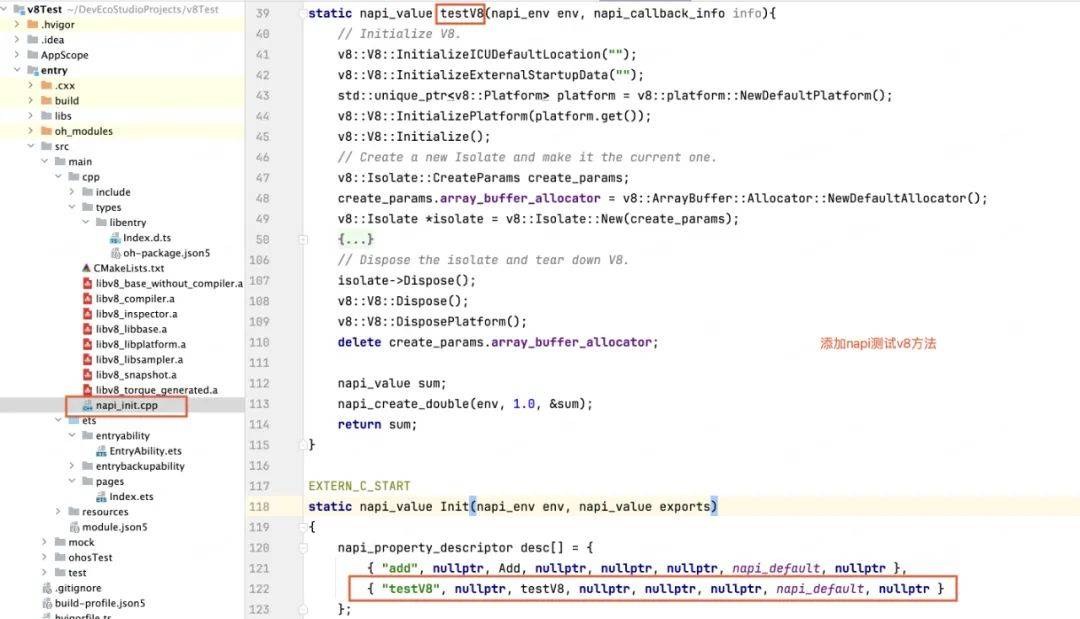
导出c++方法
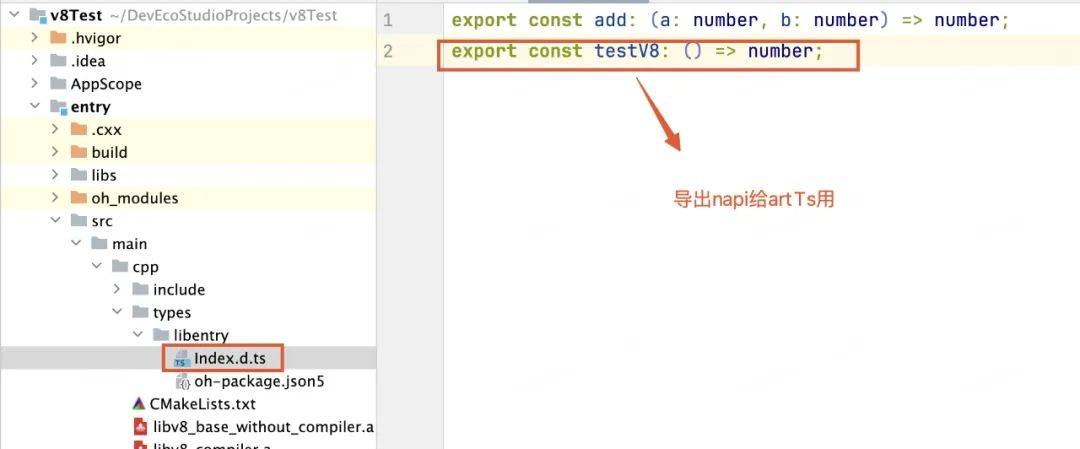
arkts侧调用c++方法
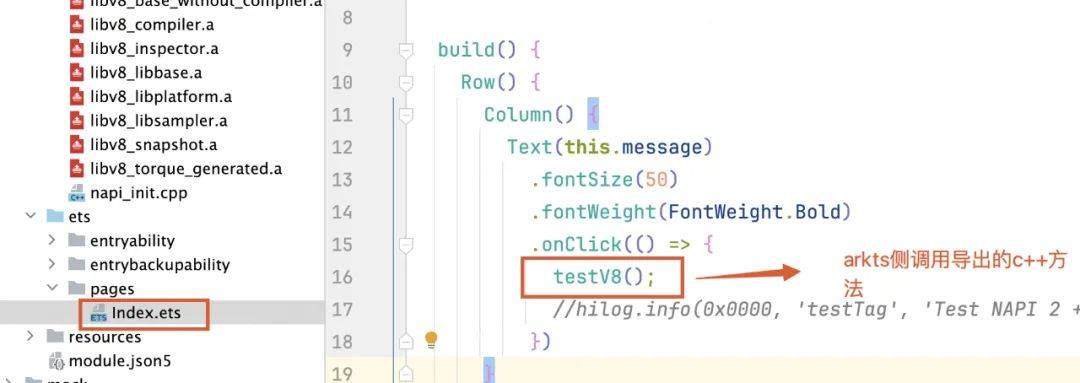
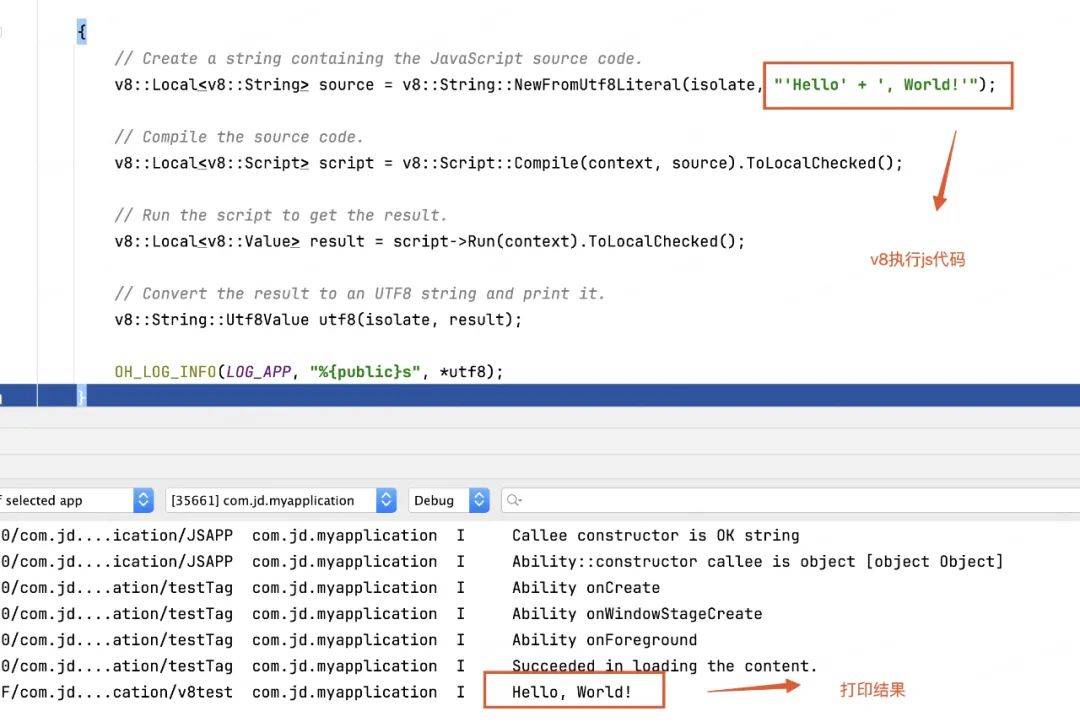
运行查看结果:
07
JS引擎的发展趋势
理解,首先 MCube 会依据模板缓存状态判断是否需要网络获取最新模板,当获取到模板后进行模板加载,加载阶段会将产物转换为视图树的结构,转换完成后将通过表达式引擎解析表达式并取得正确的值,通过事件解析引擎解析用户自定义事件并完成事件的绑定,完成解析赋值以及事件绑定后进行视图的渲染,最终将
随着物联网的发展,人们对IOT设备(如智能手表)的使用越来越多。如果希望把JS应用到IOT领域,必然需要从JS引擎角度去进行优化,只是去做上层的框架收效甚微。因为对于IOT硬件来说,CPU、内存、电量都是稀缺资源。那怎么可以基于V8引擎进行改造来进一步提升JS的执行性能呢?
使用Type编程,遵循严格的类型化编程规则;
构建的时候将Type直接编译为Bytecode,而不是生成JS文件,这样运行的时候就省去了Parse以及生成Bytecode的过程;
运行的时候,需要先将Bytecode编译为对应CPU的汇编代码;
由于采用了类型化的编程方式,有利于编译器优化所生成的汇编代码,省去了很多额外的操作。
由于采用了类型化的编程方式,有利于编译器优化所生成的汇编代码,省去了很多额外的操作。
如果用V8引擎来实现可以将Parser以及Ignition拆分出来,用于构建阶段,删除TurboFan处理JS动态特性的相关代码,这样可以将JS引擎简化很多,一方面不再需要parse以及生成bytecode,另一方面编译器不再需要因为Java动态特性做很多额外的工作。因此可以减少CPU、内存以及电量的使用,优化性能。
Facebook的 Hermes差不多就是这么干的,只是它没有要求用TS编程。如今 鸿蒙原生的ETS引擎 Panda也是这么干的,它要求使用ets语法,其实是基于TS只不过做了更加严格的类型及语法限制(舍弃了更多的动态特性),进一步提升js的执行性能。
将V8移植到鸿蒙系统是一个巨大的 嵌入式范畴工作,涉及交叉编译、CMake、CLang、Ninja、C++、torque等各种知识,虽然我们经历了巨大挑战并掌握了V8移植技术,但出于应用包大小、稳定性、兼容性、维护成本等维度综合考虑,如果华为系统能内置V8,对Roma框架及业界所有依赖JS虚拟机的跨端框架都是一件意义深远的事情,通过和华为持续沟通,鸿蒙从API11版本提供了一个内置的JS引擎,它实际上是基于v8的封装,并提供了一套c-api接口。
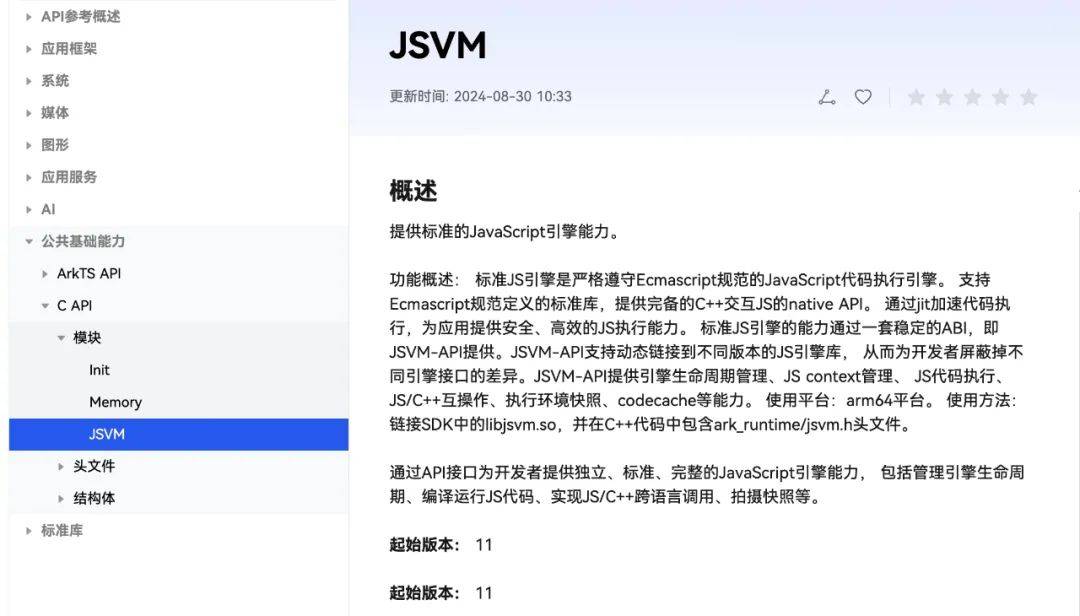
如果不想用c-api并且不考虑包大小的问题仍然可以自己编译一个独立的v8引擎嵌入APP,直接使用v8面向对象的C++ API。
Roma框架是一个涉及Java、C&C++、Harmony、iOS、Android、Java、Vue、Node、Webpack等众多领域的综合解决方案,我们这里有各个领域优秀的小伙伴共同前行,大家如果想深入了解某个领域的具体实现,可以随时留言交流~
底层能力:维护用户基础数据、行为数据建模、用户画像分析、精准营销策略的制定
▪ 功能支撑:会员成长体系、等级计算策略、权益体系、营销底层能力支持
▪用户活跃:会员关怀、用户触达、活跃活动、业务线交叉获客、拉新促活







评论